Data Normalization with Corner Bowl Server Manager
Table of Contents
- Background
- How is Data Normalization Implemented in Corner Bowl Server Manager?
- What is a Database Schema?
- Extending the Default Schema Definitions
- Pre-Built Security Event Log Schema Extensions
- Benefits of Extending the Default Schema Definition
- SIEM Reports and Charts
- In Summary
- Frequently Asked Questions
Background
Both Windows and Linux generate massive amounts of auditing data which can require significant time, CPU and memory to search for user activity, for example, and easily overwhelm centralized log databases when queries are not optimized. Corner Bowl Server Manager addresses these issues in several ways. This article shows you how Corner Bowl Server Manager normalizes data, provides tools for its users to define customer driven schema definitions then lastly how Corner Bowl Server Manager utilizes data normalization and extended schema definitions to quickly query big data across multiple data sources and types.
How is Data Normalization Implemented in Corner Bowl Server Manager?
According to Wikipedia, “Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd as part of his relational model.”
Normal forms
Codd defined the following normal forms in 1970 1NF, 2NF and 3NF.
First Normal Form (1NF)
All operating system and application log entries are unique and therefore each inserted row always follows First Normal Form (1NF).
Second Normal Form (2NF)
Since each row is unique, 2NF does not apply to log entries, however, some entries embed duplicate information, such as Microsoft’s Security Event Log entries, that do not need to be saved. In the example below we can see several large informational paragraphs appended to the end of the unique message. Corner Bowl Server Manager parses specific Security Event Log Entry messages then removes the duplicated informational paragraphs from each message prior to saving the entry to the central log database. This is also known as data cleansing.
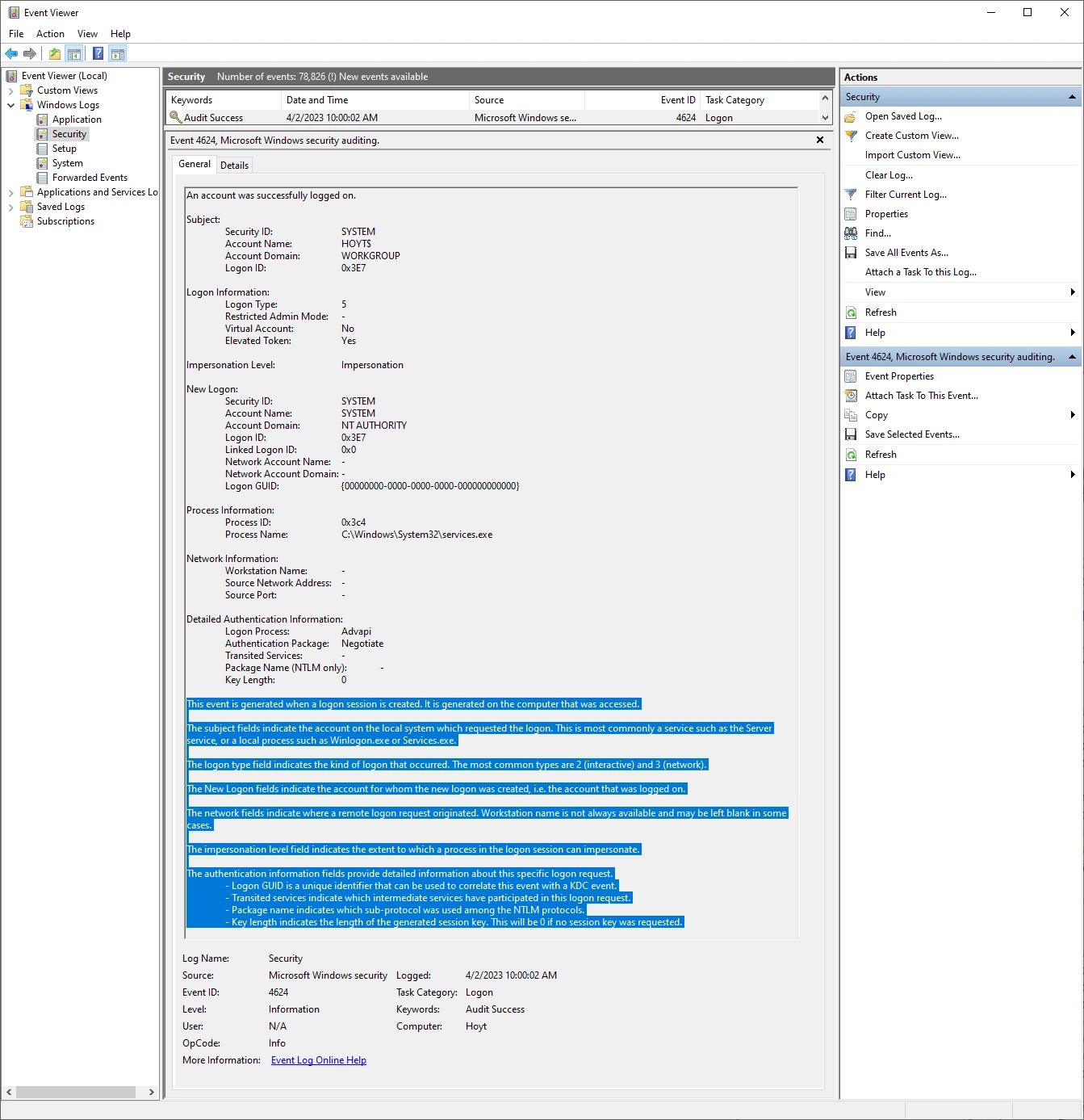
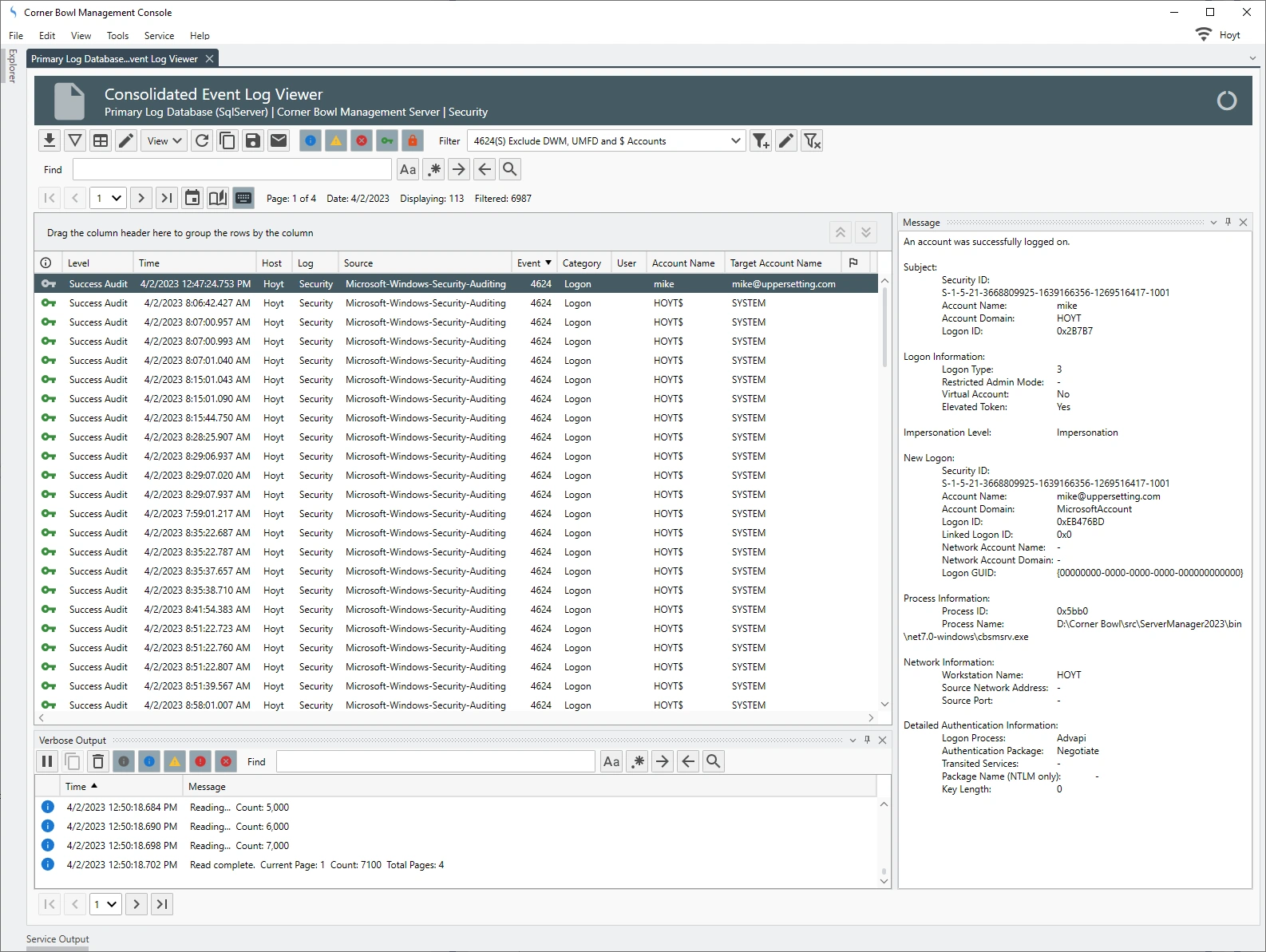
Third Normal Form (3NF)
Event Levels, Informational, Warning and Error, and Syslog Priorities, debug, info notice, warn, critical, error, emergency and alert, are stored in their own tables then foreign key values assigned in each saved log entry significantly reducing duplicated data in each saved log entry.
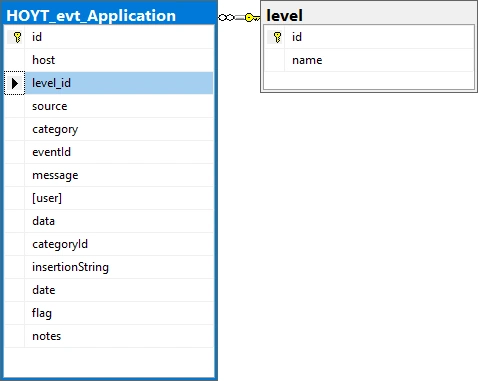
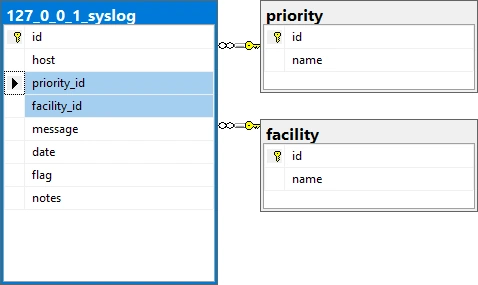
What is a Database Schema?
According to Wikipedia, “The database schema is the structure of a database described in a formal language supported by the database management system (DBMS).” (https://en.wikipedia.org/wiki/Database_schema).
Corner Bowl Server Manager implements different schemas for each log type. Using SQL Server as an example we can see the following differences between the Event Log, Azure Entra ID Audit Log, Syslog, Text Log and SNMP Traps schema definitions:
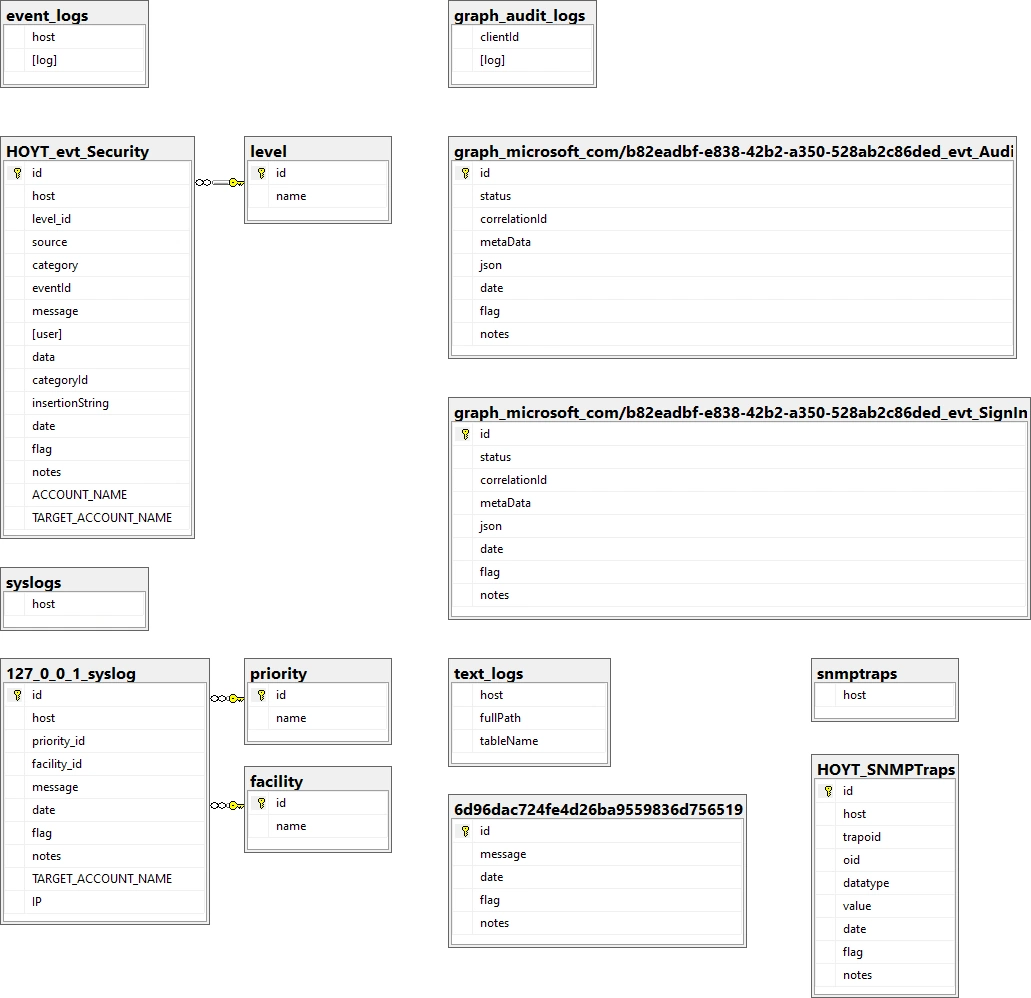
Extending the Default Schema Definitions
Corner Bowl Server Manager enables its’ users to extend the default log entry schema for any log type or instance. Customer driven parsing algorithms can be applied to log consolidation and monitoring Templates enabling its users to extract key value pairs then save them to a database table for later consumption.
Each column definition includes the following configurable parameters:
| Parameter | Description |
|---|---|
| Enabled | Enables or disables the column from the result set. |
| Key | Defines the value's key for log monitor filters and defines the column name for log consolidation database tables. |
| Name | Defines the display value for the column. |
| Data Type | Defines the value's data type for log monitor filters and defines the column data type for log consolidation database tables. |
| Column Size | When applied to a log consolidation template, defines the maximum size for a string column. |
| Index | When applied to a log consolidation template, creates a database index for the column. |
Pre-Built Security Event Log Schema Extensions
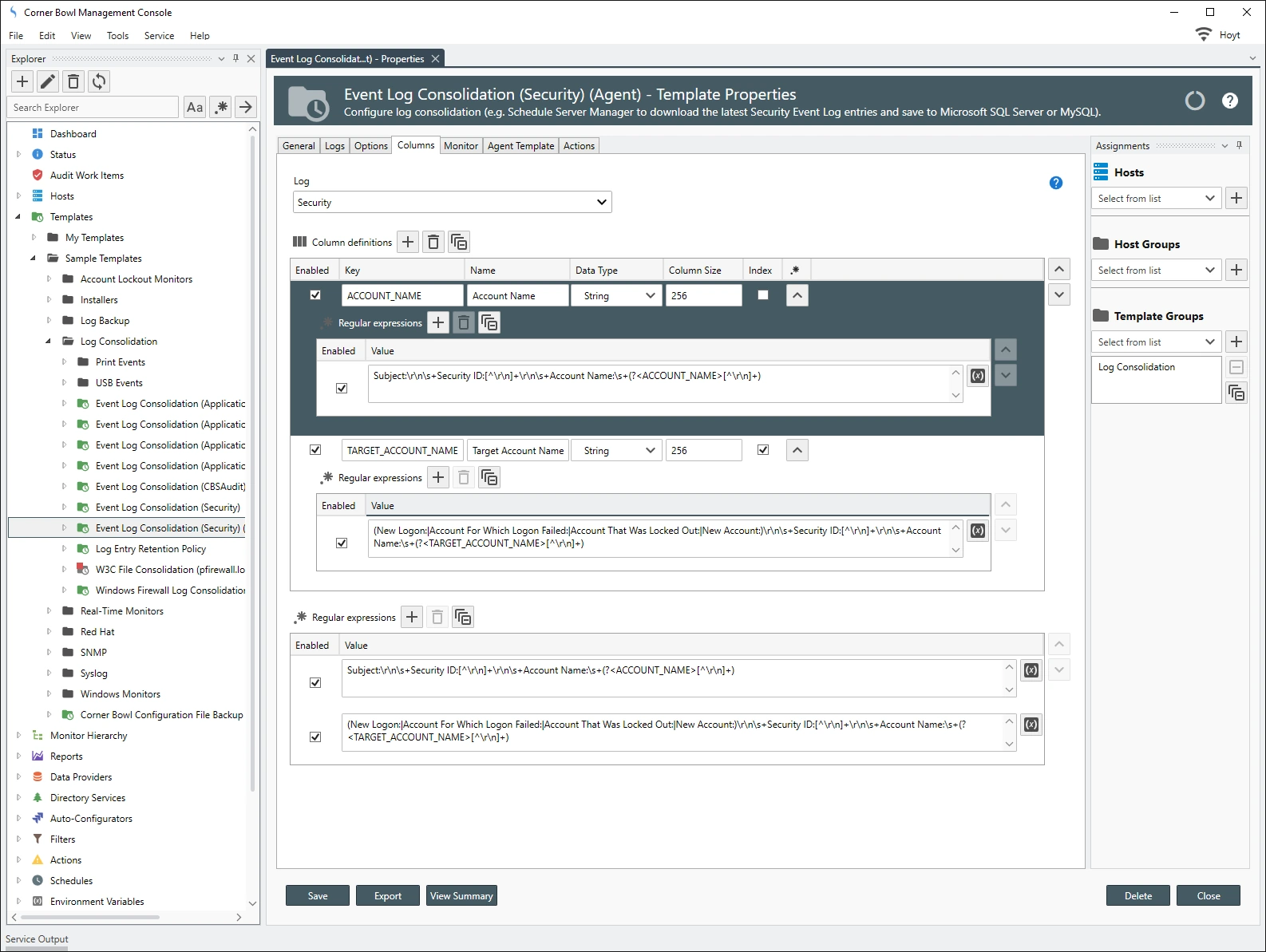
Out-of-the-box, Corner Bowl Server Manager includes several templates that parse Security Event Log Entries and Syslog Messages prior to saving them to the database. The following sample templates include several column definitions to normalize and extract the Subject Account Name and Target Account Name fields found in many Security Event Log entries, such as Success Logon and Account Management Events.
- Templates/Sample Templates/Security/Event Log Consolidation (Security)
- Templates/Sample Templates/Security/Event Log Consolidation (Security) (Agent)
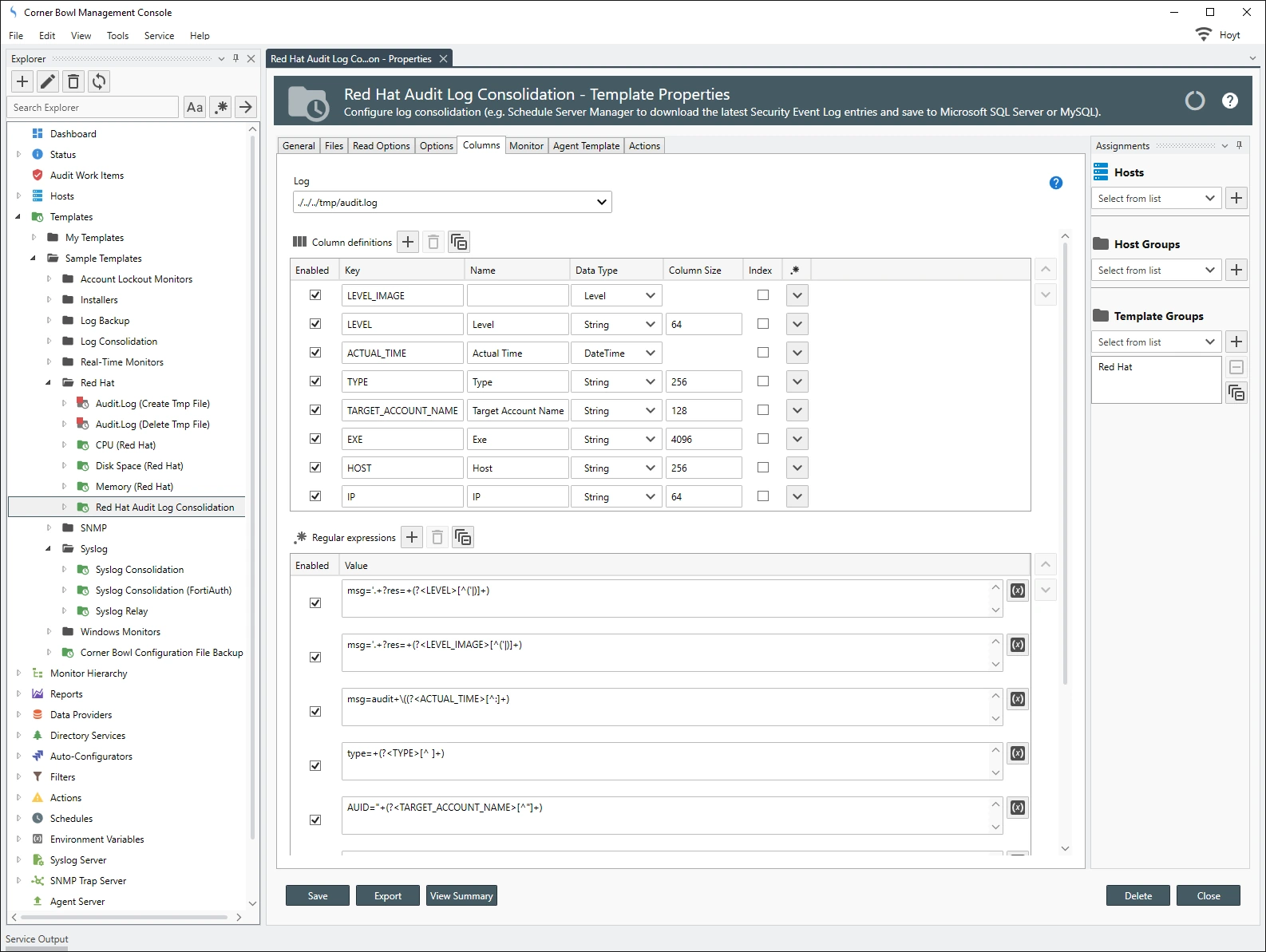
- Templates/Sample Templates/Security/Red Hat/Red Hat Audit Log Consolidation
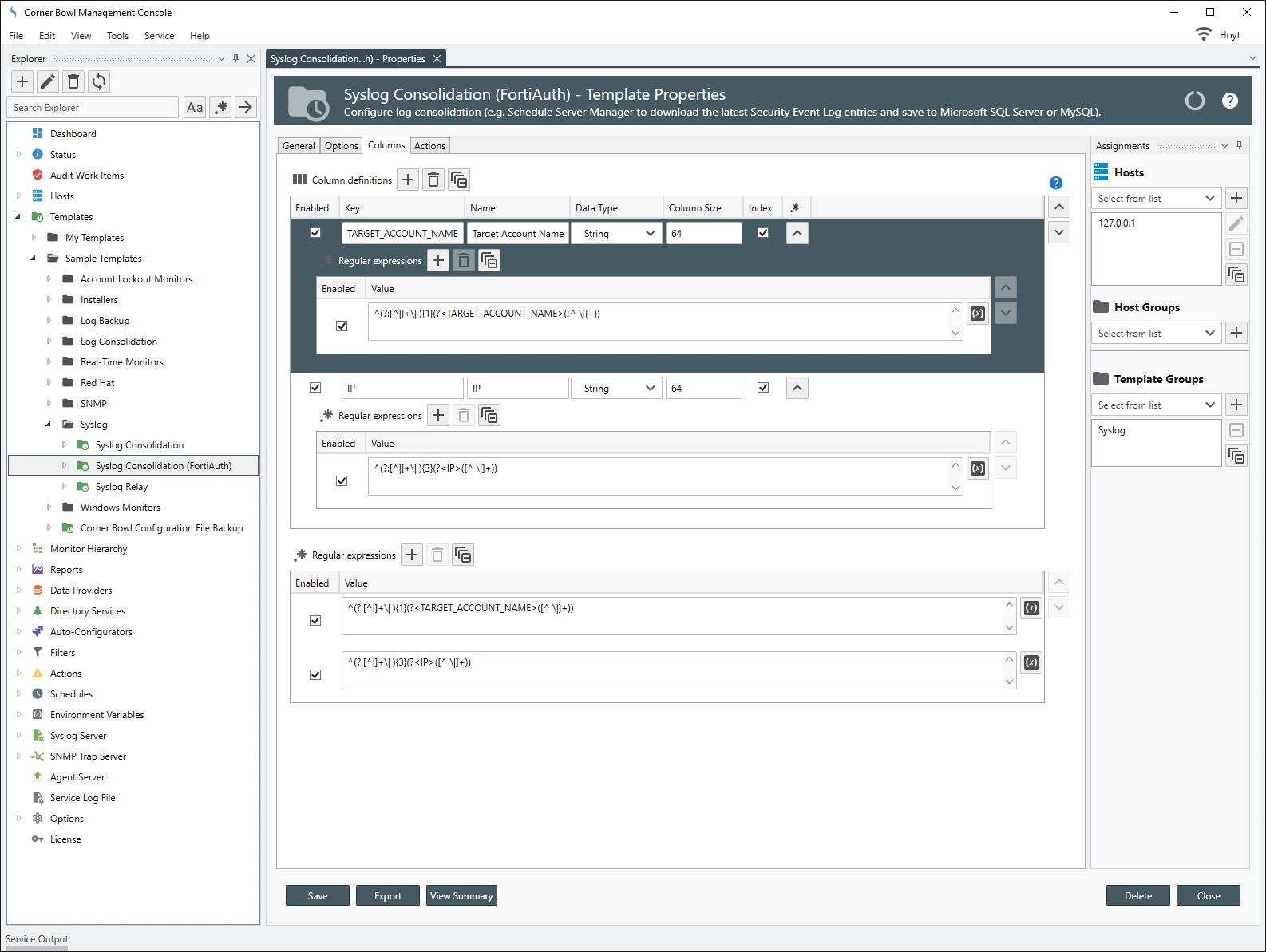
- Templates/Sample Templates/Syslog/Syslog Consolidation (FortiAuth)
The following data normalization and regular expressions are applied to the Security Event Log templates:
The following data normalization and regular expressions are applied to the Red Hat Audit Log Consolidation template:
The following data normalization and regular expressions are applied to the FortiAuth Syslog Consolidation template:
Benefits of Extending the Default Schema Definition
When viewing consolidated Security Event Log Entries, each regular expression driven column definition appears in the Event Log Viewer as its own column that can be filtered on, grouped by and sorted by enabling Server Manager users to quickly gain insight into user activity.
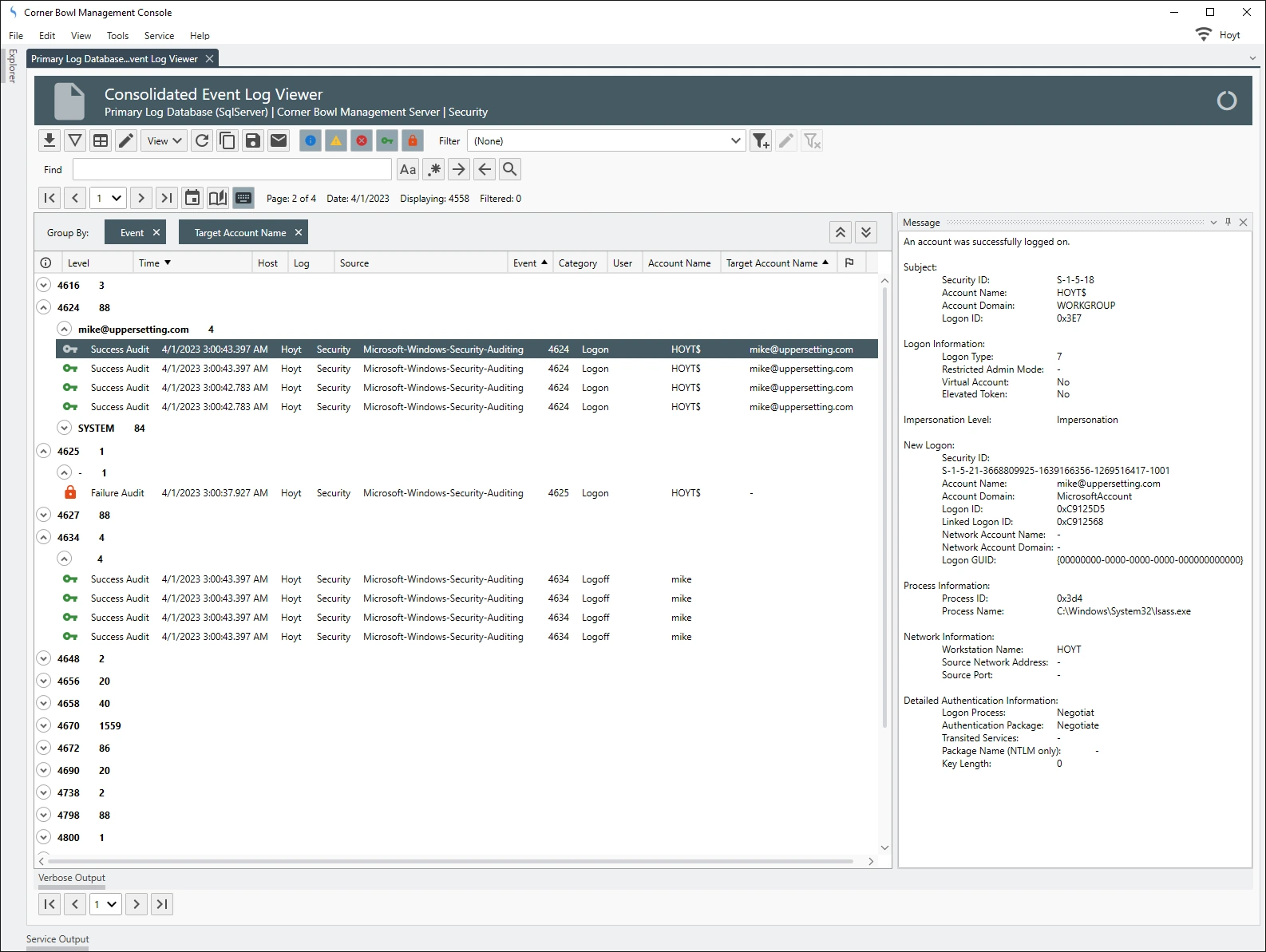
Security Event Log Reports can optimally be configured to query specific indexed columns optimizing each report query crucial when data mining large consolidated Security Event Logs. The query optimizer also enables its users to nest query parameters enabling users to fully gain the benefit of the RDBMS. In the example below, the report query is looking for a specific user which when viewing data saved using the built-in Security Event Log Template, is performing a table scan on the indexed TARGET_ACCOUNT_NAME column.
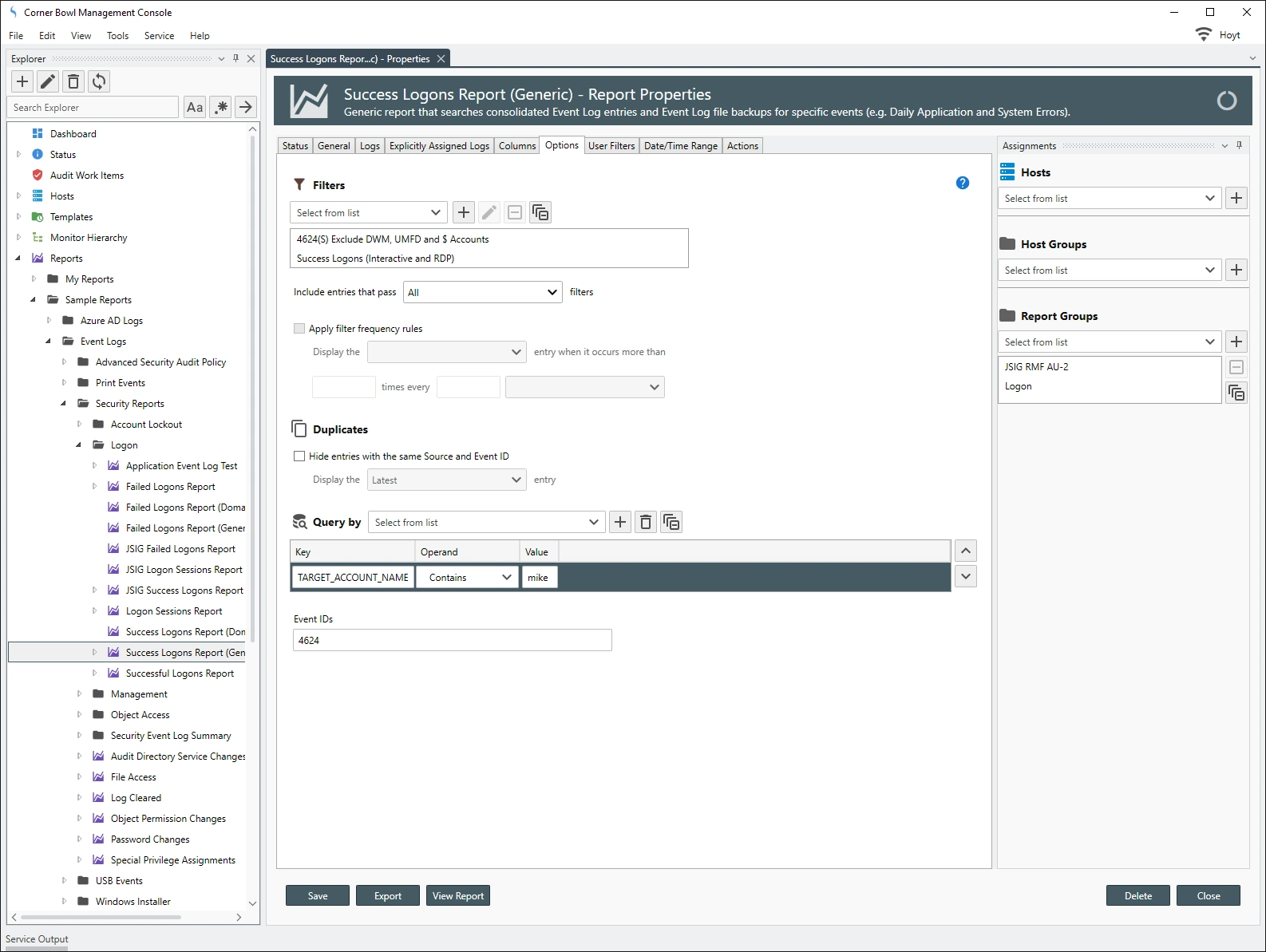
When running a report against a single consolidated SQL Server Security Event Log Table that contains 1,000,000 rows, we can see the following performance differences:
| RegEx Column | Indexed | Query Optimization | Filtered | Total Time | Description |
|---|---|---|---|---|---|
| Y | Y | Y | N | 10.141 | Regular expression applied when entries are downloaded, extracted columns saved to an indexed column and query optimization applied. |
| Y | Y | Y | Y | 13.812 | Regular expression applied when entries are downloaded, extracted columns saved to an indexed column query optimization applied and filter applied. |
| Y | Y | N | Y | 56.963 | Regular expression applied when entries are downloaded, extracted columns saved to an indexed column and filter applied. |
| Y | N | Y | N | 12.393 | Regular expression applied when entries are downloaded, extracted columns saved to an non-indexed column and query optimization applied. |
| Y | N | Y | Y | 12.87 | Regular expression applied when entries are downloaded, extracted columns saved to an non-indexed column query optimization applied and filter applied. |
| Y | N | N | Y | 51.449 | Regular expression applied when entries are downloaded, extracted columns saved to an non-indexed column and filter applied. |
| N | N | N | Y | 1:43.071 | Regular expression applied when entries are returned from the database query and filter applied. |
SIEM Reports and Charts
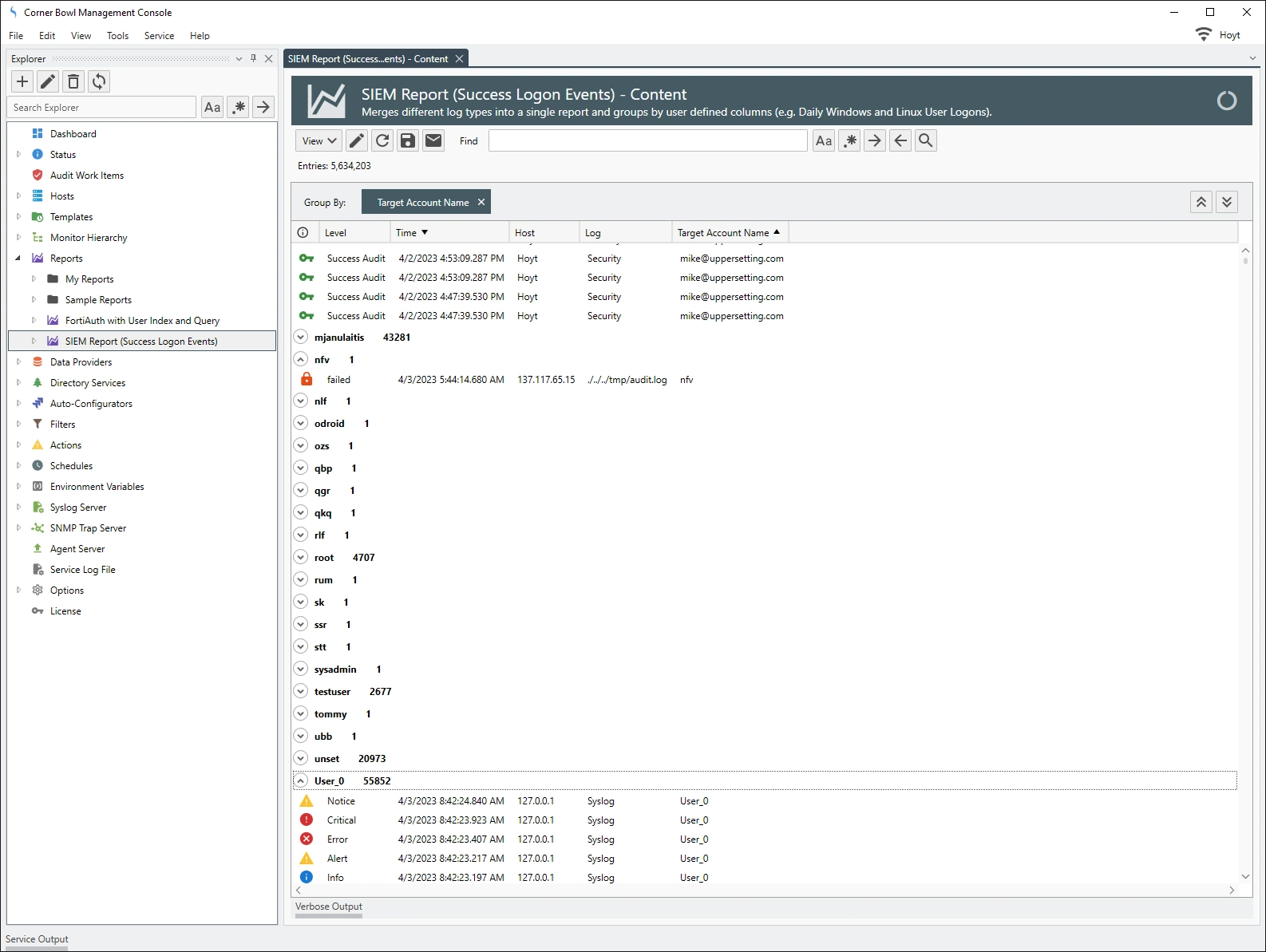
Corner Bowl Server Manager takes this one step further enabling its users to data mine user activity across multiple log types, such as Security Event Logs and Red Hat Enterprise Linux (RHEL) Audit Logs. In the example below, users that log into Windows, RHEL and a FortiAuth Switch are displayed within a single tabular report:
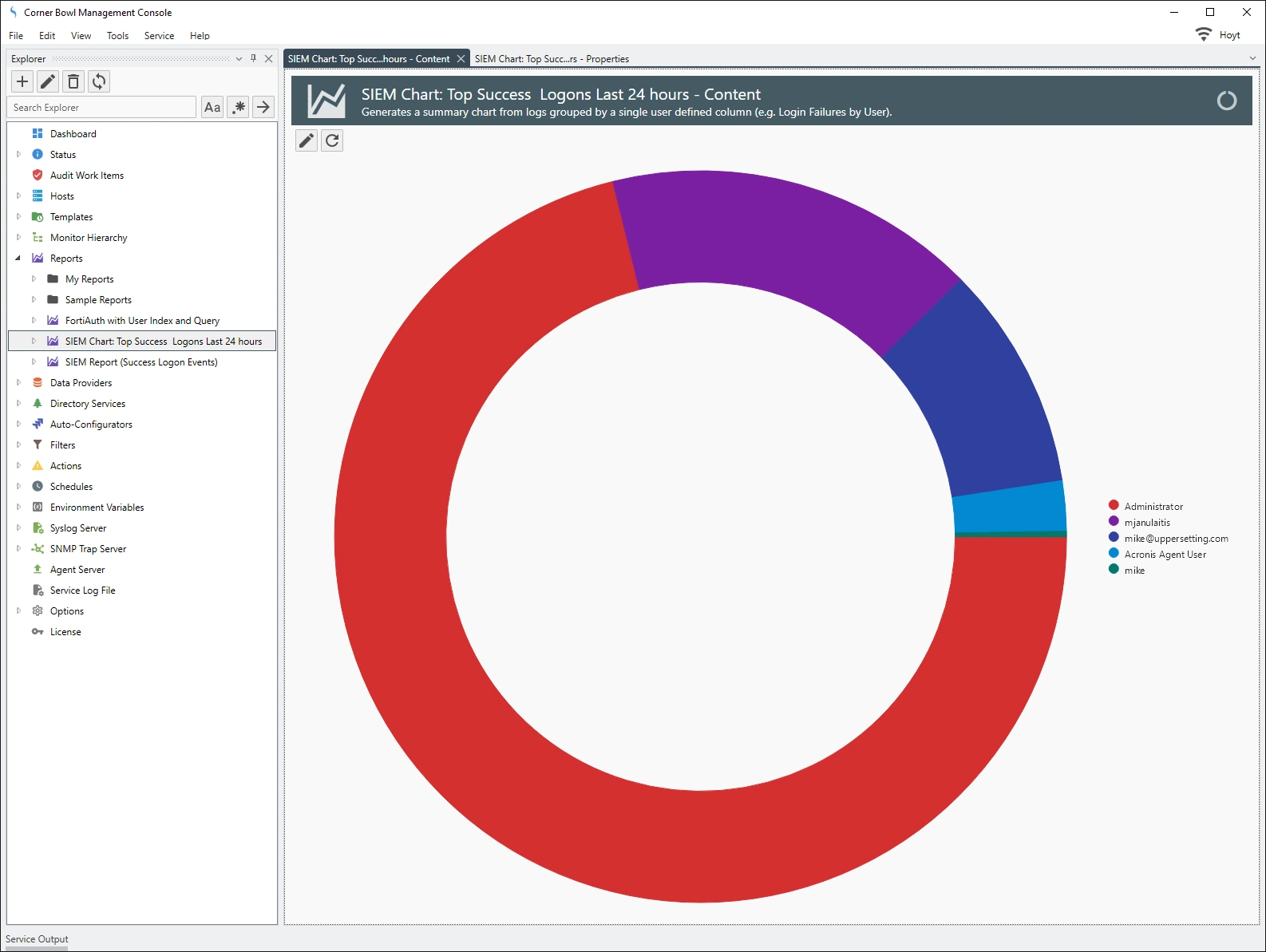
In the example below, successful logins grouped by username then applied to a donut chart:
In Summary
We have shown you how Corner Bowl Server Manager:
- Data normalizes log entries when saving to a central log database,
- Parses Security Event Log Entries, Syslog Messages and Red Had Audit Log entries to extract key value pair values.
- Saves extracted key value pair values to custom defined RDBMS columns with optional indexing.
- Data mines large tables to quickly generate user activity reports.
- Then finally, correlates log entries from multiple sources to generate security driven SIEM reports.
Frequently Asked Questions
What is data normalization?
Data normalization is a process used to organize and structure data in a consistent and standardized manner. It aims to reduce data redundancy and improve data integrity by eliminating duplicate or unnecessary information and establishing relationships between data entities.
Why is data normalization important?
Data normalization is important for maintaining data consistency, reducing storage space, and enhancing query performance in databases. It also simplifies data management, reduces the risk of data anomalies, and helps maintain data integrity when inserting, updating, or deleting records.
What are the different normalization forms?
Normalization forms are a series of progressive steps or rules to guide the data normalization process. The most common forms are First Normal Form (1NF), Second Normal Form (2NF), Third Normal Form (3NF), Boyce-Codd Normal Form (BCNF), Fourth Normal Form (4NF), and Fifth Normal Form (5NF). Each form builds upon the previous one, addressing specific data redundancy and dependency issues.
When should I use data normalization?
Data normalization is most commonly applied during the design and development of database systems, specifically relational databases. It can also be used in data preprocessing for machine learning and data analytics tasks to improve the quality and consistency of the input data.
What are the potential drawbacks of data normalization?
While data normalization has many benefits, it can also lead to increased complexity in database design, as well as increased join operations when querying data, which can sometimes result in slower query performance. However, modern database management systems are generally well-equipped to handle these complexities.
Is data normalization always necessary?
Data normalization is not always necessary. It largely depends on the specific use case, the type of database system, and the desired balance between data integrity, redundancy, and query performance. In some cases, a denormalized data structure may be more efficient, particularly for read-heavy applications with minimal updates and data insertion requirements.
How does data normalization relate to data preprocessing in machine learning?
In machine learning, data normalization often refers to scaling or transforming input features to a common range or distribution, which can improve the performance of certain algorithms. This type of normalization is different from database normalization, although both aim to improve data quality and consistency.
Can data normalization help with data privacy and security?
Data normalization can indirectly support data privacy and security by improving data integrity and reducing the risk of data anomalies. However, it does not inherently address data privacy or security concerns. To protect sensitive data, additional measures such as encryption, access control, and data anonymization should be implemented.